Pada MySQL, sering kita jumpai istilah collation, yang mau tidak mau harus berinteraksi dengan nya, terutama ketika membuat database, tabel, dan field/kolom, terkadang hal ini membingungkan bagi sebagian orang, untuk itu pada kesempatan kali ini kita akan membahas lengkap apa itu character set dan collation pada MySQL.
Daftar Isi:
- Apa itu collation pada MySQL
- Kenapa perlu ada collation
- Apakah kita perlu peduli dengan collation
- Collation dan character set pada MySQL
- Lebih jauh tentang latin_swedish_ci
- Lebih jauh tentang utf8 dan utfmb4
- Jadi, character set dan collation mana yang dipilih?
1. Apa itu collation pada MySQL?
Collation dapat diartikan sebagai:
Collation adalah: Sekumpulan rule atau aturan yang digunakan oleh database untuk untuk membandingkan karakter yang ada pada sebuah character set. Sedangkan character set sendiri dapat diartikan sekumpulan character dengan jenis tertentu.
Pada MySQL, Collation dapat dipahami sebagai cara (rule) yang digunakan untuk:
- Mengurutkan nilai pada suatu kolom, seperti pada statement order, misal: Â
ORDER BY Â nama_kolom DESC - Membandingkan nilai pada kolom, seperti pada statement where,misal: Â
WHERE nama_kolom = "A"
Untuk lebih detailnya akan dibahas di bagian bawah.
2. Kenapa perlu ada collation?
Kenapa untuk mengurutkan dan membandingkan saja perlu ada rule tertentu yang bermacam-macam? sebenarnya hal ini tidak perlu jika karakter hanya terdiri dari a-z dan 0-9, mengurutkannya tinggal diurutkan sesuai abjad: a, b, c, dst, atau sesuai nomor urut: 1, 2, 3, dst
Masalah timbul ketika kita dihadapkan pada kebutuhan untuk menampung  karakter khusus, seperti karakter latin (accented character) yang digunakan oleh negara-negara eropa, contoh:  ÃƒÂ¤,  ÃƒÂ£,  ÃƒÂ¡, Ã¥. Bagaimana mengurutkan karakter tersebut? atau bagaimana posisinya terhadap karakter normal?
Untuk itu perlu digunakan rule agar pembandingan antar karakter sesuai dengan standar yang ditetapkan.
3. Apakah kita perlu peduli dengan collation?
Jika kita hanya menggunakan karakter umum, seperti yang ada pada keyboard, dan kebanyakan dari kita memang tidak perlu karakter khusus seperti diatas, jika demikian maka kita tidak perlu dipusingkan dengan collation dan character set, kita tinggal gunakan collation default MySQL (latin1_swedish_ci) sudah lebih dari cukup.
Namun jika aplikasi/web yang kita kelola atau kita berencana membangun website yang mengandung content karakter khusus tidak hanya karakter latin, misal: Huruf Arab, China, Kanji (Jepang), latin (Perancis, Belanda, dan Negara Eropa lain), maka collation akan menjadi sangat penting.
Terlepas dari semua itu, mempelajari collation tetap akan memiliki nilai tambah, setidaknya kita tahu apa yang kita lakukan, salah satu nya ketika memilih collation setiap kali membuat kolom, tabel, atau database pada phpMyAdmin.
4. Collation dan Character Set Pada MySQL
Jenis Collation pada MySQL
MySQL memiliki banyak collation, setidaknya ada 219 jenis, daftar collation dapat dilihat ketika kita membuat database atau tabel pada phpMyAdmin:

atau dapat ditampilkan menggunakan perintah SQL berikut:
mysql> show collation;jika ingin menampilkan collation khusus untuk character set utf8, Â dapat menggunakan perintah:
mysql> show collation WHERE Collation LIKE "utf8%";contoh output yang dihasilkan adalah  (hanya sebagian kecil):
+--------------------------+----------+-----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +--------------------------+----------+-----+---------+----------+---------+ | utf8_general_ci | utf8 | 33 | Yes | Yes | 1 | | utf8_bin | utf8 | 83 | | Yes | 1 | | utf8_unicode_ci | utf8 | 192 | | Yes | 8 | | utf8_icelandic_ci | utf8 | 193 | | Yes | 8 | | utf8_latvian_ci | utf8 | 194 | | Yes | 8 | | utf8_romanian_ci | utf8 | 195 | | Yes | 8 | | utf8_slovenian_ci | utf8 | 196 | | Yes | 8 | | utf8_polish_ci | utf8 | 197 | | Yes | 8 | | utf8_estonian_ci | utf8 | 198 | | Yes | 8 | | utf8_spanish_ci | utf8 | 199 | | Yes | 8 | | utf8_swedish_ci | utf8 | 200 | | Yes | 8 | +--------------------------+----------+-----+---------+----------+---------+
Perhatikan bahwa dua karakter terakhir pada kolom collation adalah ci, bin, Â atau cs (tidak terlihat).
ci berarti case in-sensitive dimana perbandingan karakter tidak memperhatikan huruf besar dan kecil (a sama dengan A), cs adalah case sensitive (a tidak sama dengan A), sedangkan bin adalah: membandingkan nilai binary dari karakter (01100001 untuk a).
Sedangkan nama di depannya (seperti: general, unicode, latvian) merupakan “rule” yang digunakan untuk melakukan pembandingan.
Sehingga utf8_unicode_ci berarti: (1) character set yang digunakan adalah utf8, (2) rule yang digunakan adalah unicode, dan (3) mode perbandingannya case in-sensitive.
Nilai “Yes” pada kolom Default (pada contoh diatas latin_general_ci) berarti collation tersebut akan digunakan ketika pembuatan Database/Tabel/Field yang tidak mendefinisikan jenis collation.
Pendefinisian Character set dan Collation pada MySQL
Pada MySQL, Collation dan Character set pertama kali didefinisikan ketika kita membuat Filed, Tabel, atau Database, berikut ini contoh pilihan collation ketika membuat tabel pada pada phpMyAdmin:
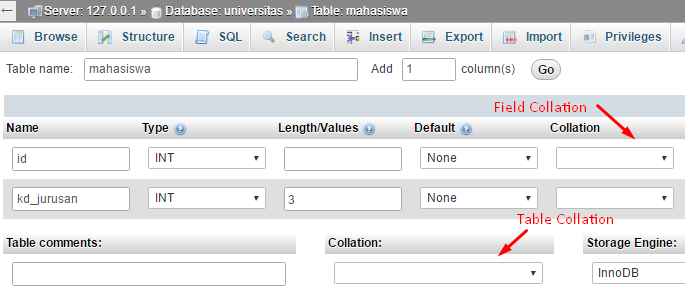
pada phpMyAdmin, pilihan collation akan otomatis menentukan character set yang digunakan, misal: collation latin1_general_ci  akan otomatis menggunakan character set latin1, karena sesuai namanya, collation latin1_general_ci  ditujuan untuk character set latin1.
phpMyAdmin melakukan demikian karena kita tidak bisa menggunakan collation pada character set yang berbeda, misal collation latin1_general_ci dengan character set utf8 seperti ini:
CREATE TABLE `mahasiswa` (
`id` int(11) NOT NULL,
`no_induk` char(9) NOT NULL,
`nama` varchar(255) NOT NULL,
`kd_jurusan` char(3) NOT NULL
) ENGINE=InnoDB CHARSET=utf8 COLLATE=latin1_swedish_ciBagaimana jika character set dan collation tidak didefinisikan?
Penentuan character set pada MySQL dilakukan secara berjenjang (inherit) mulai dari Field -> Tabel  -> Database -> Server.
Sehingga ketika kita membuat Database/Tabel/Field dan tidak menentukan jenis character set nya, maka jenis character set tersebut akan diambilkan dari jenjang atasnya.
Contoh: kita memilki database universitas dengan character set utf8, kemudian kita akan membuat tabel mahasiswa tanpa mendefinisikan collation.
Dengan phpMyAdmin:

Dengan query:
CREATE TABLE `mahasiswa` (
`id` int(11) NOT NULL,
`id_dosen` char(9) NOT NULL,
`nama_dosen` varchar(255) NOT NULL,
`kd_matkul` char(3) NOT NULL
) ENGINE=InnoDBKetika query dijalankan, secara otomatis character set yang digunakan baik pada tabel maupun field adalah utf8, inherit dari database universitas, sedangkan collation yang digunakan adalah  utf8_general_ci, karena collation ini merupakan collation default untuk character set utf8 sebagaimana telah kita bahas sebelumnya.

Ketika menjalankan query, bagaimana MySQL tahu Collation yang digunakan?
Ketika menjalankan query, MySQL akan mencari collation secara berjenjang dan urut mulai dari:
- Perintah SQL. Pertama kali MySQL akan mencari pendefinisian collation pada perintah SQL, misal:
SELECT nama, alamat, mo_tlp FROM identitas ORDER BY nama COLLATE utf8_general_ci - Kolom  / Field.  Jika tidak ditemukan pada perintah SQL, maka MySQL akan mencari pendefinisian Collation pada Kolom/Field yang ditargetkan.

- Tabel. Â Jika pada Field tidak ditemukan, maka MySQL akan mencarinya pada tabel dimana target field berada.
- Database. Â Jika tidak ditemukan juga, maka MySQL akan mencarinya di Database dimana field tersebut berada.
- Server. Dan terakhir, MySQL akan mencarinya di konfigurasi  server yang secara default disimpan pada file my.ini.

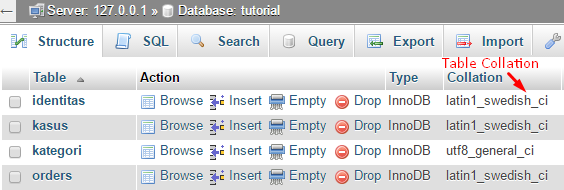


5. Lebih jauh tentang latin1_swedish_ci
Untuk lebih memahami Character set dan Collation pada MySQL, mari kita bahas salah satu collation yang sering kita jumpai yaitu latin1_swedish_ci yang merupakan default collation pada MySQL (s.d MySQL versi 5.7, mulai versi 8, MySQL menggunakan utf8mb4 sebagai default characterset) .
Character set pada  latin1_sedish_ci
Pada collation latin1_swedish_ci character set yang digunakan adalah latin1 yang memiliki ukuran 8-bit atau 1 byte per character, misal kita menyimpan kata Fulan, maka akan memakan ruang 5 byte pada hardisk + 1 byte untuk identifikasi character length oleh MySQL.
Karakter yang dapat ditampung oleh character set ini sebanyak 256 yang terdiri dari karakter ANSI, seperti pada keyboard kita + Â karakter latin (accented character – West European) yang biasanya digunakan oleh negara Eropa, adapun karakter tersebut adalah:

Sumber: Terena
Seperti contoh pada gambar diatas, character set latin1 dapat menampung karakter khusus seperti copyright ©, registered ®, kurang lebih ±, tanda bagi ÷, dll.
Jika aplikasi kita bersifat webbased, maka karakter khusus ini dapat di ganti dengan entitas HTML, misal: © untuk copyright, ® untuk registered, dll, selengkapnya dapat dilihat di: HTML 4.0 Latin-1 Entities
Collation pada latin1_sedish_ci
Dalam mengurutkan/membandingkan karakter, khususnya karakter tertentu seperti latin (accented character), masing-masing negara memiliki rule sendiri, sehingga hasil pengurutannya bisa jadi tidak sama,
Untuk collation  latin1_swedish_ci, sesuai namanya,  pencocokan dilakukan mengikuti rule swedish  atau negara Swedia.
Sebagai contoh, misalkan kita memiliki nama berikut:
Muffler Müller MX Systems MySQL
Maka ketika diurutkan, collation latin1_swedish_ci, latin1_german_ci, dan latin2_german2_ci akan menghasilkan urutan yang berbeda:
| latin_swedish_ci | latin_german_ci | latin_german2_ci |
|---|---|---|
| Muffler | Muffler | Müller |
| MX Systems | Müller | Muffler |
| Müller | MX Systems | MX Systems |
| MySQL | MySQL | MySQL |
Sumber: Dev MySQL
Keterangan: latin1_german_ci menggunakan rule DIN-1 yang sering disebut “dictionary collation”, dimana urutan abjad berdasarkan kamus, sedangkan latin1_german2_ci menggunakan rule DIN-2 atau yang sering disebut “phone book collation” atau berdasarkan urutan pada buku telefon.
6. Lebih Jauh Tentang utf8 dan utf8mb4
Jika bicara tentang character set, maka tidak akan terlepas dari Utf8, character set terpopuler saat ini. Untuk itu, pada kesempatan ini, tidak ada salahnya kita juga membahas utf8 pada MySQL.
Character set utf8
Pada standar umum yang berlaku, character set utf8 mampu menampung semua jenis karakter yang ada di dunia ini, mulai dari karakter 1 byte, seperti pada latin1, hingga 4 byte seperti pada huruf Arab, China, dll
Pada MySQL, character set utf8, dengan collation defaultnya utf8_general_ci, hanya mampu menampung character dengan ukuran 1 s.d 3 byte dan belum dapat menampung karakter berukuran 4 byte.
Untuk penggunaan space, utf8 pada MySQL menggunakan ruang secara dinamis, untuk karakter dengan ukuran 1 byte, maka ruang yang diperlukan juga 1byte, tidak seperti utf32 yang menggunakan ruang penyimpanan 2 byte.
Character set utf8mb4
utf8mb4  artinya utf8 multibyte 4, character set ini merupakan pengembangan dari utf8 yang telah ada sebelumya sehingga dapat menampung karakter yang  dari 1 s.d 4 byte, perlu dicatat bahwa istilah utf8mb4 bukanlah standar umum, istilah ini hanya digunakan oleh MySQL.
Ruang penyimpanan yang diperlukan sama dengan utf8 yaitu sesuai dengan ukuran karakter, karakter 1 byte akan membutuhkan ruang penyimpanan 1 byte.
Mana yang sebaiknya dipilih? Â utf8 atau utf8mb4
Dari penjelasan diatas, maka dapat disimpulkan bahwa  utf8mb4 lebih baik karena mampu mengakomodir semua character yang ada pada standar utf8, sehingga jika harus menggunakan character yang ada pada pada utf8, maka lebih baik menggunakan  character set utf8mb4.
7. Jadi Character set mana yang harus dipilih?
Setelah mempelajari character set dan collation, character set mana yang harus dipilih? Untuk menentukan Character Set dan Collation pada MySQL, beberapa hal yang harus dipertimbangkan:
Perfomance
Fixed – length encoding (Character set dengan ukuran byte tetap, seperti ASCII atau latin) Â akan lebih efisien dan cepat dalam pengolahan data dibanding variable – length encoding (seperti: utf8 , utf8mb4, utf32, dst…).
Hal ini terjadi pada kondisi:
- Ketika melakukan pembandingan karakter seperti pada klausul WHERE.
- Ketika mengurutkan data seperti pada klausul ORDER BY
- Ketika melakukan pengolahan string seperti SUBSTRING(), LEFT(), TRIM(), dll
Disamping itu, ketika melakukan join table dan character set yang digunakan berbeda, misal latin1 dan utf8, maka MySQL akan mengkonversi salah satunya, yang akibatnya index dari tabel tersebut TIDAK dapat digunakan.
Artinya, tanpa index, proses sorting tabel akan memakan waktu lebih lama.
Space
Baik Fixed-length encoding maupun variable-length encoding (dalam hal ini latin dan utf8) menggunakan space yang sama, misal untuk karakter a-z, A-Z, 0-9 sama-sama membutuhkan ruang 1 byte per karakter.
Namun, Â ketika Ketika MySQL membuat temporary tabel, misal: ketika melakukan subquery atau join, maka pada Memory (RAM), MySQL akan mengalokasikan space sebesar byte maksimal yang dapat ditampung oleh character set.
Sehingga misal: untuk kolom CHAR(10), MySQL akan mengalokasikan 10 byte untuk character set latin1 dan 30 byte untuk utf8, hal tersebut karena jumlah maksimal byte yang dapat ditampung oleh utf8 adalah 3 byte.
Sehingga…
Sehingga, hanya gunakan character set seminimal mungkin sesuai kebutuhan, Misal: ketika membuat aplikasi / web berbahasa tertentu, maka gunakan character set untuk bahasa tersebut yang sifatnya fixed-length.
Misal untuk web berbahasa Indonesia, cukup menggunakan character set  latin1 atau ASCII, sedangkan untuk khusus berbahasa arab maka cukup menggunakan CP1256.
Namun, jika sobat membuat web berbahasa Inggris dan memungkinkan pengunjung dari berbagai negara, misal: Arab, China, Jerman, dll untuk mendaftar, atau jika kita ingin aplikasi kita dapat menyimpan icon emoji seperti:  maka UTF8mb4 cocok untuk digunakan.
maka UTF8mb4 cocok untuk digunakan.
List lengkap emoji dapat dilihat di: Â Full Emoji List, V11.0
Jika aplikasi kita bersifat web based, emoji tersebut dapat diganti dengan hexadecima atau decimal character seperti:  😀 untuk smiling face, list lengkapnya dapat dilihat di  &what: Discover Unicode & HTML Character Entities, sehingga masih bisa menggunakan character set Latin1
Closing
Terdapat banyak sekali pilihan character set dan collation pada MySQL, semua itu dibuat bukan tanpa tujuan, untuk itu, selalu gunakan character set dan collation yang sesuai dengan kondisi dan kebutuhan, sehingga dapat meningkatkan perfomance database.
Penting untuk mempelajari character set, karena akan selalu dan selalu bermanfaat untuk pengembangan aplikasi, jika sobat ingin mempelajari lebih lanjut tentang character set, sobat dapat membaca artikel: Â Memahami Character Set dan Character Encoding
Demikian tutorial mengenai character set dan collation pada MySQL, semoga bermanfaat.
26 Feedback dari pembaca
Thanks mas Agus. DB Saya akan saya konvert ke latin1. semoga ada peningkatan performa
Iya mas, sama sama. Biasanya peningkatan performa baru terasa jika jumlah datanya besar, namun tetap baik untuk dipraktekkan untuk membiasakan diri menerapkan best practice
terima kasih mas, terus berkembang ! 🙂
Aaamiin, sama sama mas
artikel yang bagus, dan penjelasannya cukup lengkap. biasanya artikel sejenis ditulis di bahasa inggris jadi cukup susah memahaminya. terima kasih banyak.
Terima kasih, sama-sama mas….
Jika sudah terlanjur pakai utf8 bagaimana cara mengkonversi semua table secara bersamaan(tidak satu per satu) agar menjadi latin1 semua?
Bisa dicoba di dumb databasenya mas, sebelum di load ulang di replace characterset nya, atau bisa dibikin loop menggunakan program
Makasih banyak kang, penjelasanya sangat detail
Sama sama mas…
kang ada error count() saat subscribe.
Mohon di capture mas errornya
wah bermanfaat sekali nih bang
Terima kasih mas…
mau saya capture tapi mau ngirim lewat apa 🙁
Oh, maksudnya mau di share ya mas?
mas saya sudah muter cari di google belum solusi untuk menampilkan bahasa arab dimana jika di server xampp bahasa arabnya tampil sempurna tapi begitu dionline kan (server hosting) bahasa arabnya jadi karakter tanda tanya semua (???). Collation mysql udah dirubah. Apakah ada kemungkinan salah di file PHP nya? file php nya sudah saya beri meta charset-utf8 tp masih tetap sama tidak bisa menampilkan bahasa arab
Bisa dicek di database nya mas, pakai database managr, tampil ngga bahasa arabnya, jika iya, tinggal di cek di bagian HTML untuk menambilkan data tersebut, atau kalau ngga bisa dicoba mysqli nya di ubah character set nya:
https://www.php.net/manual/en/mysqlinfo.concepts.charset.php
Thank You gan, mantab tutorialnya jadi bisa input semua symbol 😀
Siap, sama sama mas….
kalau mysql saya ga bisa baca karakter “/” garis miring itu kenapa ya gan? tapi kalo garis miring “\” bisa
Maksudnya ngga bisa baca bagaimana ya mas?
Mas Agus Prawoto, terima kasih banyak, tulisannya detil dan jelas. Semoga berkah, banyak rejekinya, sehat selalu sekeluarga dan sekantor.
Terima kasih.
Sama sama mas…
Terima kasih bang, sangat membantu. semoga dimudahkan
Sama sama mas